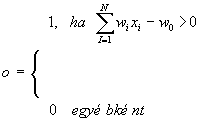
Geier János
Neuronhálózatok tanítása optimalizálással
1998. tavaszi félév
(legutolsó módosítás: 1999.03.04)
Ez a jegyzet négy fõ részbõl és egy függelékbõl áll:
1. BEVEZETÉS
A modell és valóság viszonya
Mottó: A világ olyan, amilyen, bármiféle megértési, magyarázó tevékenység egyúttal valamilyen modell megalkotását is jelenti.
Modellek típusai:
Akár tudunk róla, akár nem, a hétköznapi életben is “modellekben” gondolkodunk. Sót, a hétköznapi modelleket nem mindig szoktuk megkülönböztetni a “valóságtól”. Azt mondjuk pl., hogy “a csapból folyik a víz”, de a csap egy bonyolult kristályszerkezettel rendelkezô fémdarab, aminek nemcsak a konkrét alakját nem ismerjük pontosan, hanem a szilárdtest-fizikai elméletét sem. A vízrôl is inkább csak azt “tudjuk”, hogy “nedves és folyni szokott”, esetleg ismerjük a képletét H2O, de a hidrogénrôl is csak egy kvantumfizikai modellünk van, stb. Végül az, hogy “folyik”, ismét csak egyike a legbonyolultabb fizikai problémáknak, hiszen a vízfolyás általában örvényekkel szokott együtt járni, ami kapcsolatos a káoszelmélettel. Mindezekkel a részletekkel azonban nem szoktunk foglalkozni, ha ilyen hétköznapi kijelentést teszünk. Vagyis a “csapból folyik a víz” kijelentésünkkel eltekintünk a fenti sok részlettôl. A jelenséget egy rendkívüli módon leegyszerûsített modell keretébe helyezzük, melynek érvényessége szinte csak erre a szûk jelenségkörre korlátozódik. Kijelentésünk tehát nem a “valóságról” szól, csupán annak egy leegyszerûsített modelljérôl. Ez a modell a “fejünkben” van, ez egy kognitív modell. Ha szigorúak lennénk, valójában csak azt szabadna mondanunk, hogy “ez a jelenség az adott felhasználás szempontjából jó közelítéssel modellezhetô egy elképzelt ideális csappal, és az abból kiáramló ideális folyadékkal, mely mellesleg rendelkezik még azzal az ugyancsak idealizált tulajdonsággal, hogy képes az (ideális) ember (ideális) szomjának oltására, és mosni is lehet vele...”. Ehelyett egyszerûen összekeverjük a modellt a valósággal, és kijelentjük “ a csapból folyik a víz”
Ezért semmi kivetnivaló nincs abban, ha pl. a következô mondat helyett:
“Az agy modellezhetô egy olyan számítógéppel, mely kiszámítja ezt és ezt”, azt a rövidebb mondatot használjuk:
“Az agy kiszámítja ezt és ezt”. Utóbbi jellegû mondatokat értelemszerûen a bôvebb módon értjük majd.
Az óra tárgya az agy, azaz az idegrendszer modellezése, ami a fentiek alapján nem más, mint a mûködés megértésére való törekvés. Ehhez analóg és matematikai modelleket fogunk használni, azaz egyfajta komputációs szemléletmóddal közelítjük a problémát.
Az agy mint optimumkeresô gép
Jelen elôadás fô szempontja az agy globális mûködésmódja, ezen belül az észrevétel, hogy az idegrendszer szinte állandó jelleggel valamiféle egyensúlyi állapot, optimum felé halad (“törekszik?”). Ez a kijelentés már most az elején némi részletezést igényel.
Matematikai értelemben egy egyensúlyi állapot mindig leírható valamilyen sokváltozós függvény szélsôértékével, azaz lokális vagy globális minimumával, vagy maximumával. Fizikai példát említve gondoljunk pl. egy asztalra helyezett pohár vízre. Az, hogy a víz felszíne vízszintes, azt jelenti, hogy a vízmolekulák közös súlypontja a lehetô legalacsonyabbra került a pohár által meghatározott peremfeltételeken belül. Ez így tehát egy sokváltozós minimumfeladat, ahol az egyensúly megtalálása az energiaminimum megtalálásával ekvivalens. A minimalizálandó függvény változóinak száma azonos a vízmolekulák számával (vagy annál is nagyobb, ha a kvantum-tulajdoságokat is figyelembe veszük), maga a függvényérték pedik a közös súlypont tengerszint feletti magassága. Hasonlóképp gondoljunk egy talpán álló emberre, akit ha enyhén meglökünk, visszatér a függôleges állásba. Ez is egy egyensúlyi állapot tehát, amely azonban kellôen bonyolult ahhoz, hogy egyszerûen megmondható lenne, mi is pontosan a függô, és mik a független változók, és mi a függvénykapcsolat közöttük. Azonban, ha belegondolunk, könnyen látható, hogy a homeosztázis, a tanulás, és általában bármiféle alkalmazkodás lényegét tekintve valamilyen optimalizálást, egyensúlykeresést tételez fel az idegrendszertôl. (Mondhatni, az egész élet egy nagy optimumfeladat.)
Matematikai értelemben az egyensúlyfeladat, optimumfeladat, minimumfeladat, maximumfeladat (utóbbi kettô együtt szélsôérték-feladat) ugyanazt jelenti: egy skalár értékû sokváltozós függvény szélsôértékének megtalálását.
Az “optimum” kifejezés bizonyos mértékig félreérthetô, ha emberre vonatkoztatjuk. Itt semmiesetre sem szabad valamiféle gerinctelenségre, megalkuvásra, vagy kicsinyes önzésre gondolni, ha azt mondjuk, hogy az ember egy egyensúlyi állapotra, optimumra törekvô lény. Egyrészt ugyanis a világ kellôen bonyolult és változatos ahhoz, hogy mire elérnénk az “optimumot”, addigra megváltozzanak a viszonyok, és már máshol kell keresni azt. Másrészt az, hogy egy adott szituációban egy adott személynek hol van az “optimuma”, vagyis mi a számára optimális viselkedés, az jórészt az illetô személyiségének függvénye. Röviden: lehet, hogy egy hôsnek az optimuma, ha a csapat élén nekirohan az ellenségnek. (Ha optimumot keresünk, akkor nem szabad elfeledkezni a peremfeltételekrôl!)
Ehhez a gondolathoz kapcsolódik, hogy az önzõ gén elméletet. Eszerint nem biztos, hogy egy adott személy vagy egyed optimumát meg lehet érteni anélkül, hogy a teljes faj génállományának “önzését”, azaz optimum felé haladását ne vennénk figyelembe. E globálisabb szempont alapján lehet levezetni pl. az anyai önzetlenséget, vagy a társas rovarok közös tevékenységét.
Az elõadás szûkebb témája a mesterséges neuronhálózatok tanítása. Matematiaki értelemben a tanulást is optimumfeladatnak tekinthetjük: az idegrendszer paramétereit úgy kell “behangolni”, hogy viselkedése a legnagyobb sikert és a legkisebb kudarcot érje el. Ezt az általános elvet a konkrétabban megfogalmazott mesterséges (absztrakt) neuronhálózatok kapcsán majd pontosítani fogjuk.
Az agy mint analóg számítógép
Vázlat.
Az analóg számítógépek valamely fizikai folyamatot közvetlenül használják fel számításra. Pl. 3 tartály, mint összeadó gép.
Attól, hogy esetleg diszkrét értékek szerelnek, pl. golyók, ez még analóg. Az analóg nem a folytonos szinonimája, és a diszkrét nem a digitálisé! (Ld. Gregory: Az értelmes szem., Neumann J.: A számológép és az agy.)
A digitális sz. gépek mindig diszkrétek, az analóg sz. gépek lehetnek diszkrétek és folytonosak.
A digitális gépek jellemzôje: az adott jeleknek helyiértéke, ill. logikai értéke van.
A digitális gépek rögtön az elemi szinten döntést végeznek (0 vagy 1 érték), és maga a számítási folyamat döntések sorozatából áll. Tehát ezeknél szükség van egy szekvenciális, logikai algoritmusra, mely e döntések sorozatát határozza meg.
Ezzel szemben az analóg sz. gépeknél maga a fizikai folyamat, vagy ha úgy tetszik, maga az ” anyag” végzi közvetlenül a számítási folyamatot. Egy analóg számítógép is képes “döntést hozni”, de a végsô döntés olyan egymásra ható folyamatok eredménye, mely részfolyamatok nem feltétlenül tartalmaznak döntéseket.
Az analóg avagy digitális szambeállítás valójában egy szemléletmódi vita: a kérdés az, hogy mely szemléletmód hasznosabb, értelmesebb. Elôadásom megközelítése szerint az agyat inkább érdemes analóg számítógépnek tekinteni, ahol maguk az fizikai (biokémiai stb.) folyamatok végzik a számítást,. továbbá, ahol a folyamatok nem jelentenek minden pillanatban egy-egy döntést. Pl. egy állat el tudja dönteni, hogy adott szituációban meneküljön vagy támadjon, de ez a öntése nem logikai részdöntések sorozatából alakult ki, hanem folytonos folyamatok egymásra hatásából.
A folyamatok végeredményeként esetleg kialakuló döntés úgy tekinthetô, mint a rendszert leíró folytonos függvény egy stabil állapota, (lokális optimuma) mely ezek után meghatározhatja a további folyamatok “medrét”. (Tank and Hopfield: Számolás neuronszerû áramkörökkel)
A fentiekkel azt is állítom, hogy az agyat, ha nagyon kell, lehetséges ugyan valamiféle digitális Turing gépnek, vagy valamilyen algoritmusokat végrehajtó logikai gépnek tekinteni, de nem nagyon érdemes. Sokkal inkább érdemes olyan analóg számítógépnek tekinteni, melyben párhuzamosan futó folyamatok egymásra hatásának eredményeként áll elõ az adott belsõ állapot és a válasz.
AZ ANALÓG ÉS DIGITÁLIS SZÁMÍTÓGÉPEK ÖSSZEHASONLÍTÁSA
|
DIGITÁLIS |
ANALÓG |
|
A számok bárázolósa digitális formában történik, azaz ugyanaz a bináris (digitális) jel más és más számértéket képvisel az elfoglalt helyétõl függõen (helyiérték). |
A számok ábrázolása valamely fizikai mennyiséggel történik. Pl. hosszúság, elfodulási szög, áramerõsség, feszültség, stb. |
|
Az ábrázolt mennyiségek mindig diszkrétek. |
A mennyiségek jellemzõen folytonosak, de lehetnek diszkrétek is. Utóbbira példa, ha két urnában lévõ golyókat összeöntjük egy harmadik urnába: ez egy analóg összeadógép annak ellenére, hogy diszkrét mennyiségeket adtunk össze. |
|
A számokkkal való mûveletvégzés logikai mûveletekre van visszavezetve; a logikai mûveletek elvégzése kétállapotú, un. logikai áramkörökkel történik. |
A mûveletvégzés az adott fizikai folyamatok tulajdonságainak közvetlen felhasználásával történik. |
|
A pontosság tetszõleges, az ábrázolható tartomány a digitális hélyiértékek számának függvénye |
A pontosság a fizikai folyamat , és a felhassznált eszközök által korlátozott. |
|
Elkülönített adattárolás és mûveletvégzés. |
A tárolás a mûveletvégzés színhelyén, attól nem elkülönítve történik. |
|
A részegségek között szinkronizálás szükséges; a folyamat idõben is diszkrét. |
Nincs szükség a részegységek közötti szinkronizálásra; a folyamat idõben lehet folytonos. |
|
A számítás menete szekvenciális; egyidõben csak egy elemi lépés hajtható végre. (A többprocesszoros gépekre ugyanez áll, minden egyes processzor vonatkozásában.) |
A számítási folyamatok idõben is és térben is párhuzamosan folyhatnak. |
|
A számítás folyamatát a kódolt algoritmus (azaz a program) határozza meg. |
A számítás folyamatát a részegységek egymással való kapcsolata közvetlenül meghatározza; nincs egymástól elkülönítve a program és az azt végrehajtó egység. |
|
A digitális gépek a múveleti hierarchia legalsó szintjén valójában analóg gépek: a logikai múveleteket olyan analóg áramkörök végzik melyeknek csak két stabil állapota lehetséges, és az átbillenés az egyik stabil állapotból a másikba a szikronjel holtideje alatt történik. A döntés a lehetõ legalacsonyabb szinten már megtörténik, és a számítási folyamat nem más, mint döntések sorozata. |
Az analóg gépekben kölcsönösen egymásra ható folyamatok futnak, melynek eredményeképp végülis elõállhat egy stabi állapot, ami tekinthetõ egy végsõ döntésnek. De ez a döntés nem elemi döntések sorozatának eredménye. |
Az analóg és digitális számítógépek fent felsorolt jellemzõi alapján el lehet dönteni: az agy inkább digitális, vagy inkább analóg számítógépnek tekintendõ-e?
A diszkrét gépet ne tévesszük össze a digitális géppel, és az analógot a folytonos géppel; a digitális - analóg megkülönböztetés nem szinonímája a diszkrét - folytonos megkülönböztetésnek.
Az agy mint párhuzamos mûködésû gép
Tudjuk, hogy a neuronok múködési sebessége nem túl gyors, legalábbis a modern digitális számítógépek részegységeinek sebességéhez képest nem az. A neuronok maximum 1000Hz frekvenciával képesek tüzelni, ezzel szemben a mikroprocesszorok több mint 100MHz-cel. Ugyanakkor az emberi és állati idegrendszer 100ms nagyságrendû idõ alatt képes bonyolult percepciós feladatok megoldására, pl. arcfelismerésre (vagy háziállat esetén “gazdi”-felismerésre.) Ugyanilyen feladatok megoldása az ismert számítógép algoritmusokkal egyelõre lehetetlen, de a leegyszerûsített feladatok (pl. nyomtatott betûk felismerése) is rendkívül sok számolást igényelnek, amihez a jelenlegi gépek sebessége épp, hogy elégséges.
Ennek alapján nyilvánvaló, hogy az idegrendszer felépítése és mûködésmódja legalább egy pontban jelentõsen eltér az általánosan elterjedt digitális gépekétõl: alapvetõen párhuzamos a mûködése.
Ez egy jelentõs érv amellett, hogy az agyat érdemes analóg számítógéphez hasonlíani, ugyanis az analóg számítógépek könnyen párhuzamosíthatók. Sokkal könnyebben, mint a digitális gépek, mivel elôbbieknél nincs szükség az egyes részegységek szinkronizálására. A digitális számítógépek mûködése csak akkor párhuzamosítható, ha az adott feladat megoldására szolgáló algoritmust sikerûl önálló részekre bontani, majd szinkronizálni. Páruzamos felépítésû digitális számítógépek léteznek már, de a fõ problémát a megfelelõ, hatékony párhuzamos algoritmusok megalkotása jelenti.
A párhuzamosság némiképp félreérthetô fogalom, ezért ezt pontosítani kell.
Azt lehetne gondolni, hogy két részegység párhuzamos mûködése ekvivalens azzal, hogy “párhuzamosan vannak kapcsolva”. Valóban, ekkor lehet idôbeli párhuzamosságról is beszélni, de nagyon fontos észrevenni: nemcsak a párhuzamosan egymás mellé kapcsolt részegységek képesek idôi párhuzamosságra, hanem a sorba, azaz egymás mögé kapcsolt részegységek is.
Erre példa egy rugóból, tömegbôl és csillapításból álló mechanikai rendszer analóg számítógépes modellje. Itt az egymás mögé kapcsolt analóg integrátorok fizikailag sorba vannak kapcsolva, azonban nyilvánvaló, hogy mûködésük idôben párhuzamos: miközben az egyik egység folyamatosan számítja az inputja alapján a megfelelô output értéket, a hozzá kapcsolódó részegység már e részeredményt felhasználja, és így idôben egyszerre mûködve áll elô a teljes végeredmény, a modellezett rendszer csillapított rezgése. Itt tehát semmiesetre sem arról van szó, hogy az elsô egység kiszámítja az ô végeredményét, azt a második megvárja, és csak miután az elsô egység készen van, jön a következô, és dolgozza fel az elôzô kimenôjelét.
Az itt leírt példa alapján az agymûködést sem úgy kell elképzelni, hogy pl. elôször a retina kialakítja a maga outputját, miután ezzel kész, jelez a V1 látókéregnek, amely ugyanigy elôször kiszámítja az ô outputját, majd V1 jelez a V2 -nek, hogy kész, stb. Helyette azt kell elképzelni, hogy miközben a retina látvány feldolgozásával foglalkozik, ezzel egyidôben már ennek részeredményét dolgozza fel a V1 stb. stb. És az egészet minden bizonnyal egy nagy, átfogó, és több lokális feed-back, azaz visszacsatolás fogja át. (Nem negatív, se nem pozitív, mert errõl csak 1 dimenziós visszacsatolás esetén beszélhetünk. A visszacsatolás általánosabb fogalmáról késõbb lesz szó.)
Ehhez a gondolatmenethez kapcsolódik a kognitív szakirodalomban ismert un. 100 lépéses szabály elve. Ez arra vonatkozó becslés, hogy ha egy percepciós feladatot, pl. egy arcfelismerést az ember kb. 100ms alatt el tud végezni, ugyanakkor a neuronok maximum 1000Hz frekvenciával képesek tüzelni, akkor maximum 100 egymás utáni “lépésbôl” kellett ezt a percepciós feladatot megoldania az idegrendszernek. Az idôi párhuzamosságról szóló fenti fejtegetés fényében a “100 lépéses szabály” teljességgel értelmetlen elvnek minôsíthetô. Ez a “szabály” ugyanis éppen a kritizált, naiv szemléletmód alapján került annak idején megfogalmazásra, mintha az egymás feletti hierarchiába rendezett neuronok csak akkor kezdhetnének a nekik szánt input feldolgozásába, ha az elôtte lévô szint teljesen befejezte volna mûködését.
A 100 lépéses szabály helyett itt a teljes rendszer átviteli frekvenciájának becslést lehetne elvégezni, de ez semmiképp sem jelentené azt, hogy ezzel bármiféle becslést tettünk volna az egymás fölé rendezett hierarchikus szintek darabszámára vonatkozóan: ez akár 1000 vagy 10000 is lehet. A 100 lépéses szabály mögött meghúzódó szemléletmódból következne, hogy a szintek száma max. 100 lehet - de éppen ezt a szemléletmódot vetettük el az imént.
Ezen elemzés lényege tehát, hogy a sorosan összekapcsolt részegységek az idô szempontjából mûködhetnek párhuzamosan is.
2. RÉSZ. AZ ISMERT NEURONMODELLEK
McCulloch-Pitts féle absztrakt neuronmodell
Jellemzõi:
Bemenõjelei: 0 vagy 1
Kimenõjele: 0 vagy 1
A hálózat logikai formulák megoldására képes.
Tanulási lehetõség nincs beépítve. A súlyokat a tervezõnek elõre be kell állítania.
Perceptron, mint az elsõ mesterséges tanuló neuronhálózat
A tanítóval való tanulás fogalma
....
A perceptron felépítése
Diszkrét automata: egymás utáni diszkrét idõpontokban értelmezzük a bemenõ és kimenõjeleket, valamint a belsõ állapotokat. Kellõen sûrû mintavétel alkalmazva ezáltal jól közelíthetõ egy folytonos neuron vielkedése.
Az alkalmazott neuronok azonosak a McCulloch-Pitts-féle absztrakt neuronokkal, de ‘tanulási képességgel’ felruházva. Azaz a neuronok bemenetéhez tartozó súlytényezõk képesek belsõ, lokális szabályok alapján módosulni, amit azt majd késõbb látni fogjuk.
A tanítható (értsd módosítható szinaptikus súlyokkal rendelkezõ) neuronok a legutolsó rétegben helyezkednek el, azaz a kimeneteik azonosak a teljes neuronhálós kineneteivel.
A perceptron, és ezáltal az egyes neuronok bemenõjelei 0 vagy 1 értékek, a kimenõjelek szintén.
Egy kimeneti neuron a következõ szabály alapján állítja elõ a kimenõjelét:
ahol
w0 a neuron küszöbe, N a bemeneteinek a száma,xi Î
{0, 1}, a neuron i. bemenetén lévõ bemenõjel,wi Î
(-¥ ,+¥ ) az i. bemenethez tartozó súlytényezõ, röviden súly.Vegyük észre, hogy a neuron egy lineáris hipersík mentén végez szeparálást az n dimenziós absztrakt térben.
A perceptron algoritmus
A cél, hogy a tanító által bemutatott bemeneti alakzatok és a hozzá tartozó elvárt kimenõ vektorok (azaz a tanítás) alapján a perceptron “tanulja” meg a helyes válaszokat, azaz, egy késõbbi idõpontban bemutatott bemeneti alakzat hatására most már tanítás nélkül is az elvárt kimenõvektort adja. Némi általánosítóképességet is elvárunk, azaz, olyan bemeneti alakzatokra is lehetõleg helyes választ adjon, amelyekre nem lett tanítva. (Ezt az általánosító képességet egyelõre senki sem bionyította megnyugtató módon.)
Maga a tanulás a perceptron feladata. A tanulási szabály heurisztikus ötleten alapul, melynek lényege a következõ.
Az adott neuron i. bemenetének súlyát akkor és csak akkor kell változtatni, ha a i. bemeneten pozitív a jel (xi>0) és a neuron kimenõjele eltér a tanító által elvárt kimenõjeltõl; éspedig növelni kell a súlyt, ha a kiemenõjel 0 és a tanítás 1, csökkenteni kell a súlyt, ha a kimenõjel 1 és a tanítás 0. Minden más esetben a súly értéke változatlan marad.
Ezt a következõ két formula írja le:
![]() (1)
(1)
![]() (2)
(2)
ahol
D
wi a wi súlytényezõ változtatásának mértéke a t és t+1 idõpont között;xi
a neuron i. bemenetén levõ jel;o a neuron kimenõleje és t az elvárt kimenõjel, azaz a tanítás;
h
egy konstans, ami a konvergencia sebességét határozza meg. (Ha ez túl nagy a rendszer belenghet, tehát nem találja meg a megoldást, ha túl kicsi, akkor viszont sokáig tart a megoldás megtalálása. Értékét a konkrét futtatás során tapasztalatilag szokás meghatározni.).A (t-o) különbséget a késõbbiekben elõjeles büntetésnek fogjuk nevezni.
A fenti szabály mögött az a gondolat áll, hogy
A perceprton pozitív tanulságai
Kétségtelen, hogy képes egyfajta “önálló” tanulásra, azaz, nem kell kívülrõl megmondani számára, hogy hogyan változtassa a súlyokat. Amit meg kell mondani, az csupán annyi, hogy az adott bemeneti alakzatra mi lett volna a helyes válasz. Ezt viszont minden kimenõjelre külön-külön meg kell mondani.
A perceptron korlátai
Hátránya, hogy a kimeneti neuronok csak lineáris hipersík mentén végezhetnek szeparálást, emiatt a megoldható feladatok osztálya meglehetõsen korlátozott. Már az egyszerû “kizáró vagy” logikai mûvelet megoldására sem alkamasak, tehát ennél összetetteb feladatokra sem. Ha a kimenõjeleket létrehozó neuronok elé betennénk egy “belsõ”, rejtett réteget, akkor várható lenne a megoldható feladatok osztrályának kibõvülése.
További hátránya, hogy csak logikai, 0 vagy 1 értékekek lehetnek a bementén is és a kimenetén is. Ez távol áll a valódi idegrendszer felépítésétõl, ahol ezek a jelek általában folytonosak. (annak ellenére folytonosak, hogy esetleg a valódi neuronok kimenetén egy impulzussorozat jelenik meg. Ezt azonban frekvenciamodulációnak tekinthetjük, azaz ami folytonos, az maga a frekvencia.)
Természetesen mód van arra, hogy a digitális kimenõjelek kombinációit kódoknak tekintsük, és ezáltal pl. a egy intervallum folytonos értékekeit kódoljuk, azonban ekkor semmiféle általánosítóképességet nem várhatunk el a perceptrontól. (ennek végiggondolását az olvasóra bízom).
A három rétegû hálózat tanítása back propagation algoritmussal
(a tanulás, mint optimalizálás)
A 3 rétegû perceptron felépítése, és a reakciója adott bemeneti vektorra
(az elõre terjedés)
Áll:
...............
A Back Propagation algoritmus célfüggvénye
A tanulást egy sokváltozós optimumfeladatnak fogjuk fel, ahol a cél a neuronhálózat egyes neuronjainak bemeneténél lévõ súlytényezõk behangoláas oly módon, hogy a teljes neuronhálózat bemeneti vektorára adott reakciók a lehetõ legjobban megfeleljenek a tanító elvárásainak. Ennek érdekében pontosan definiálnunk kell az optimalizálandó célfüggvényt.
A szakirodalom szerint (pl. Rummelhart and Mc Lelland, 1986) a háromrétegû perceptron célfüggvénye:
Ep=
Si |oip-tip|2ahol p egy teteszõleges, rögzített bemeneti alakzat, az i index az összes kimeneti neuronon fut végig. Ez a formula az elõzõ bekezdésben imént megfogalmazott igényt fejezi ki, valamely tetszõleges rögzített p bemeneti alakzatra.
A BP algoritmus ezen célfüggvény parciális deriváltjainak alapján kialakított gradiens módszerrel azonos (ld. az Optimalizáló módszerek c. fejezetet.)
A tanulás, azaz a hátrafelé terjedés folyamata
A tanítás optimalizálást jelent. Jelen esetben minimalizálni kell az elvárt és a tényleges ouput vektor közötti négyzetes eltérést (Euklidészi távolságot, ld. a fenti formulát).
Annak érdekében, hogy az optimum megtalálása viszonylag könnyû legyen, a neuronok átviteli függvényét (szándékosan!) deriválhatóra választják, valamint a réteges felépítést feltételként szabják.
Az absztrakt neuronok mûködésmódja is és felépítése is tehát eleve aszerint lett kialakítva, hogy a célfüggvény egy deriválható, un. összetett analitikus függvény legyen. Ezáltal az optimum megtalálásának feladata matematikai értelemben egy összetett függvény deriválására vezethetõ vissza. A back prop. algoritmus ennek a levezetésnek az alapján áll elõ.
A BP algoritmus levezetése
A levezetést ld. külön, a megadott hivatkozásokban.
A levezetett algoritmus értelmezése
A hibajel visszafelé terjedése ugyanazon az útvonalon történik, amin a jel elõre terjedt. A pontos szabály a mövetkezõ:
Látható, hogy mind a jel elöre terjedése, mind a hátra terjedése a szinapszisok és a neuronok szintjén lokális információk alapján történik. (Elégséges feltételezni egy neuron-démont minden neuronban és egy-egy szinapszis-démont minden szinapszisban, melyek csak a közvetlen környezetükbõl kapnak jelet és oda is adják tovább. )
Ezáltal tehát megvalósul a Paralel Distributed Processing, azaz PDP elve.
A BP módszer korlátai
Eleve megvannak azok a korlátok, melyek a perceptront is jellemzik.
Ezen túl érvényesek a következõk:
A BP nem életszerû, mert vektor-visszajelzést vár, ellentétben a valódi élôlényekkel, akik skalár visszajelzés alapján (hideg-meleg, “túz-víz”)is képesek tanulni. Vegyük ugyanis észre, hogy egyrészt a kimeneti és az elvárt vektor közötti négyzetes távolság minimalizálását végezzük (ez egy skalár, azaz egydimenziós érték), ugyanakkor a tanulási folyamatban ennél többet használunk fel: felhasználjuk az egyes koordináták közötti eltéréseket, külön külön mindegyiket (ez egy vektor, melynek dimenziószáma azonos a kimenetek számával). Skalár mennyiséget minimalizálunk vektoriális visszajelzés alapján. Ez részletesebb információt jelent, mint ha csak a négyzetes eltérést használná fel a neuronhálózat a tanulásra!
A back. prop. algoritmus ebben az értelemben tehát nem pontosan modellezi a valódi tanulást. A valóságban ugyanis a “tanító” csupán egy összesített, globális jutalom-büntetés értéket jelez vissza az állat számára, és nem ad pontos visszajelzést az egyes kimeneti koordinátákra.
A BP algoritmus alapján tanuló mesterséges neuronhálózat tanitója “céltudatos tanító”: pontosan megmondja a tanulónak, mit kellett volna válaszolni az adott inputra. Ezzel szemben a természetes helyzetekben a tanító általában maga a környezet. Pl., ha túl közel megy egy állat a túzhöz, megégeti magát, ami fájdalmas számára. Legközelebb tehát el kellene, hogy kerülje a hasonló helyzetet. Igenám, de a túz, mint “tanító”, nem modja meg, mely izmokat és hogyan kell megmozgatni ahhoz, hogy elkerüljúk a megégés; csupán azt mondja meg, hogy az adott tevékenység megfelelelõ vagy se, esetleg, hogy milyen mértékben megfelelõ.
A természetes helyzetek általában olyan “naív” tanítónak tekinthetõk, melyek csak skalár visszajelzést (különbözõ mértékû jutalmat vagy büntetést) adnak a tanuló felé. Ez viszont nem elégséges a BP algoritmus alapján mûködõ tanuló rendszerek számára.
Végezetül vegyük észre, hogy az árviteli függvényt és a hálózat réteges felépítését annak érdekében választottuk olyannak, amilyen, hogy a levezetés elvégezhetõ legyen. (Lámpa alatt keressük a kulcsot.). A természetes neronhálózatok nem követik ezt a merev korlátozást, azaz rétegen belül is lehetnek jelentõs keresztkapcsolatok.
A kritikai megjegyzések alapján kimonthatjuk a következtetést: szükség van egy olyan tanuló (vagy általánosságban optimalizáló) algoritmusra, mely skalár visszajelzés alapján is képes a súlytényezõk (paraméterek) behangolására. Ez elvezet minket az (ismert és kevésbé ismert) optimalizáló algortimusok, folyamatok tanulmányozása felé.
A három rétegû hálózat tanítása back propagation algoritmussal
(a tanulás, mint optimalizálás)
Tézisek:
3. RÉSZ. MATEMATIKAI ÉS ANALÓG OPTIMALIZÁLÁS
A fizikai világ folyamatainak közös jellemzõje, avagy mit tanulhatunk a szapppanhártyától?
Szappanhártya kísérletek, min gondolatébresztõk.
Minden szappanhártya elem lokálisan, és idõben párhuzamosan mûködik, azaz a célfüggvény megtalálásához szükségesz “számítást” elosztott módon végzik. A szappanhártya egy paralel distributed process alapján keresi meg a felszín méretének lokális minimumát.
Hasonló folyamatok figyelhetõk meg pl. egy termeszvár életében, vagy akár a társadalmi folyamatokban.
(A kérdés persze az, hogy az egyes részek mi módon kapnak vissszajelzést az optimalizálandó függvény pillanatnyi értékérõl.)
A közös jellemzõk:
Mivel a természeti folyamatok széles skáláján (fizikaitól az idegrendszeri sõt társadalmi folyamatokig) fellehetõ az ‘optimum felé haladás’, ez azt sugallja, hogy az egyszerûbb típusú folyamatok tanulmányozása ötletet adhat a bonyolultabbak megközelítéséhez.
Tézisek:
A közös jellemzõk:
Optimalizáló módszerek
Általános, matematikai módszerek sokválatozós skalár értékû függvények optimalizálására.
Az optimalizáló eljárások osztályozása
deriváltat felhasználó algoritmusok.
deriváltmentes algoritmusok.
A céljainknak leginkább a “neuronszerû” megoldások felelnek meg. Ez többek között azt jelenti, hogy könnyel lehessen párhuzamosítani, és ne legyen szükség bonyolult vezérlõ mechanizmusra a módszer megvalósításához.
Továbbá a deriváltat igénylõ módszerek sem igazán jöhetnek szóba, mert a gyakorlatban, ha valamilyen függvénykapcsolat van az argumentumok (a bemeneti jelek) és a megfigyelt, optimalizálandó mennyiség között, ez az összefüggés ritka esetben ismert explicite, tehát a deriváltja sem ismert. A függvénykapcsolat legtöbbször csak egy ‘fekete doboz’ által van realizálva. Azaz, ha a ‘fekete doboz’ benetetére ráadjunk az argumentumokat, annak hatására megjelenik a kimeneten a megfelelõ kimenõjel, de a pontos összefüggés a konkrét esetben nem ismert, mert pl. egyéb, a körülményektõl függõ paraméterektõl is függ.
Ennek alapján két megoldás jöhet leginkább szóba: az RS és az RGM. (A többi ismert optimalizáló algoritmus nagyon kíváló eredményeket tud produkálni, amennyiben pl. ismert a függvény analitikus formulája, és ezáltal digitális számítógépen futtatható program írható rá. Esetünkben azonban nem errõl van szó, mivel az a konkrét függvény, melynek minimalizálását el kell végezni a neuronhálózat tanítása során, általában nem is ismert elõre.)
RS algoritmus, (párhuzamosítható, átlagos sebessége sqrt(n) )
Két lépés váltakozásából áll: (Rastrigin and Mutsenieks.....)
(i)véletlenszerû lépés minden paraméternél,
(ii) attól föggõen, hogy a lépés a minimum felé közeledést eredményezett, vagy sem, az elõzõ lépés megtartása vagy meg nem tartása.
Szükséges egy átmeneti tároló minden bemeneti paraméternél, és egy szinkronizáló vezérlõ egység a két ütem összehangolására. Valamint minden lépésben egy döntésre is szükség van.
RGM ( párhuzamosítható, átlagos sebessége O(1), ld.Geier, 1986-1990)
Jellemzõje: a cél felé haladás és a haladási irány keresése egyidõben történik, minden egyes bemeneti koordináta vonatkozásában. Ezáltal nincs szükség két egymás utáni, idõben elkülönült lépesre, tehát se szinkronizálásra, se az átmeneti részeredmények tárolására nincs szükség.
A folyamat a következõ, párhuzamosan (azaz egyidejûleg) végzendõ tevékenységekbõl áll:
Az RGM analóg számítógépes folyamatábrája a ... ábrákon látható.
Sokváltozós függvények minimalizálására, mely függvényeknek nem ismert az analitikus formulája, azaz melyek csak egy “fekete doboz” által vannak realizálva, a Regressziós Gradiens Módszer látszik legalkalmasabbnak..
Egy analóg számítógépes modell bizonyítja a módszer mûködõképességét erõsen kanyarodó völgy esetében, ha n=2.
Egy számítógép program bizonyítja a módszer mûködõképességét 1,4,..17*17 változó esetében, modellezve egy keretre feszített gumiháló minimális összhosszának megtalálását.
E programmal végzett összehasonlító futások tapasztilag is bizonyítják azt az elméletileg már régebben levezetett állítást, hogy amennyiben a visszacsatolási tényezõt olyan azonos értéken tartjuk, amikor semelyik változószám esetében sem leng be a rendszer, akkor egy tetszõlegesen kijelölt argumentum változásának átlagos sebessége csak a parciális deriválttól függ, és független az n dimenziószámtól.
Szimulált lágyítás, mint logikai optimalizátor. (Kirkpatrick et al.)
Logikai optimumfeladat megoldására fejlesztették ki. Lényegében egy n dimenziós egységkocka csúcspontjai közül kell megtalálni a legjobbat.
Hopfield modell. (Hopfield, Tank)
IRODALOM
Neumann János (1964) A számológép és az agy, Gondolat, Budapest
Szalai Sándor (szerk.) (1965) A kibernetika klasszikusai, Gondolat, Budapest
Wiener, Norbert (1974) Válogatott tanulmányok, Gondolat, Budapest
Tank, D.W., and Hopfield, J.J. (1988) Kollektív számolás neuronszerû áramkörökben, TUDOMÁNY, 1988. feb. p. 36-43.
Hopfield, D.W., and J.J.Tank, (1986) Computing with Neural Circuits: A model. Science, Reprint series 8 August, Volume 233, pp. 625-633.
Rumelhart, D.E. and McClelland, J.L. (Eds.) (1988) Paralel distributed processing. p 346-401.
Geier, J. (1995) A belsõ reprezentáció tanulása hátrafelé terjedéssel (Back propagation)
In: Pléh Csaba (szerk.) A megismeréskutatás új útjai, Typotex, budapest, 1995)
A MODELL
X-cs:
From: Self <IZABELL/GEIER>
To: "LISZNYAI, Sandor" <LISZNYAI@IZABELL.elte.hu>
Subject: Re: neuron
Date: Fri, 13 Dec 1996 17:55:56
>el tudod igy kueldeni a temakat?
Igen, el fogom kuldeni , de csak jovo heten lesz ra idom.
>
>ps ha van valami anyagod az utolso orai "modell-vitarol" (vmi
>irodalomjegyzek) dobj fel agy par sort, ha van idod
Igen, ez erdekes. Nekem sajnos csak matemetikai anyagaim vannak, tehat
pl. mikor mondjuk egy strukturarol, hogy az egy masik struktura
modellje, mikor izomorf, mikor homomorf egy modell, stb.
Azt gondolom, a "reprezentacio" nem azonos a "modell"-lel.
Ezt az egeszet szandekomban all meg kifejteni, es kozze tenni. Most
el is kezdem, ha mar itt az alkalom.
Az, hogy az allatok es/vagy az ember mennyire modellezi a kulvilagot..
hat azt hiszem, az egesz kognitiv pszichologia valahol errol szol:
kognitiv terkep, kognitiv modell, stb., ilyeneket mondanak.
Kardos prof. patkanyainak is kell, hogy legyen kognitiv terkepe (tehat
egyfajta modellje) a labirintusrol, ha meg tudjak oldani az ut
leroviditesenek a problemajat. Vagy tud valaki mas magyarazatot?
Az en elvi problemam a kovetkezo: lehet-e olyan "gepet" tervezni,
amelyik tanulas (tapasztalatszerzes) altal kepes felepiteni magaban
a kornyezetenek egy "hasznalhato" modelljet. (Persze, kinek mi a
hasznalhato, de a patkaynak az, ha eligazodik a labirintusban. )
Masik elvi kerdes: hogyan lehet tesztelni, hogy egy allatban letezik
e egy modell, vagy sem. A mehekrol elmondottak egy lehetseges valasz
jelentenek erre, meg akkor is, ha esetleg nem hisszuk el az
eredmenyt.
Ha tenyleg igy reagalnanak a mehek, akkor fel kellelne teteleznunk,
hogy van kognitiv terkepuk (ami a modell egy falfaja) a kornyezetrol.
Ezt meg meg lehetne fejelni azzal, hogy azok a mehrajok, melyek csak
rovid ideje vannak az adott terepen, becsaphatoak, melyek regota,
azon nem csaphatok be ez emlitett modon. Ezzel egyetertesz?
A pok halofonasi modszere pl. nagyon izgat engem. Csak egymasutani
lepeseket vegez, vagy van egy "modellje" (netan ""elkepzelese"") a
halorol, ez ezt, mint celt koveti? Ezt pl. ugy lehetne tesztelni,
hogy elrontjuk a halot, es vajon kijavitja-e, vagy csak elorol tudja
kezdeni? Esetleg akozben szakitjuk el valamelyik fontos fonalat,
mikozben az uj halot kesziti. Mit csinalna ekkor? Visszaterne egy
korabbi muveletre, amivel kijavitja a hibat, aztan atugorna a mar
kesz reszekhez szukseges lepeseket...? Vagy nem egy korabbi
muveletre terne, de valahogyan kijavitana, hiszen fontos fonalrol
leven szo, addig nem mehet tovabb, mig ki nem javitotta. Ha igy tenne,
en hajlamos lennek azt modani: a poknak belso modellje van a teljes
halorol. Persze, nem biztos, hogy ez vizualis modell, lehet hogy
mozgasos, tapintasos, vagy valami "pokszeru".
Ha egy szamitogeppel vezerelt robot tenne hasonlot, akkor azt
mondanam: a halo modellje egy olyan objektum (ezt mint az
objektumorientalt programozas alapfogalma ertem) altal van realizalva
a gepben, mely egy 3 dimenzios adattombbol (a halo keresztezodesi
pontjai), es ezen adatok kozott letesitett viszonyokbol all(ezek
lennenek a halo szalai), valamint egy tesztelo algoritmusbol, mely
leteszteli a halo "halosagi merteket", azaz, mennyire lehet azt jo
halonak tekinteni. Ez algoritmikusan megoldhatonak tunik, ez akkor ez
az objektum lenne a halo modellje a szamitogepben. Ez se nem
vizualis, se nem tapintasos, hanem "szamitogepszeru" modell.
Egyebkent pedig az egesz temakor kapcsolodik az un. "Turing
probahoz", amikor egy szobaban ulve el kell donteni, hogy a masik
szobaban ember van-e, vagy egy szamitogep. Csak monitor es
billentyuzet az erinkezesi lehetoseg. Errol pl. megvan az eredeti
Turing cikk. Ez e kerdes sok mas formaban is megfogalmazodik, pl. a
"Kinai szoba" formajaban. Az, hogy "gondolkodnak-e az allatok vagy a
gepek" szorosan osszefugg azzal, hogy 'van e aktiv modelljuk" a
vilagrol. (Aktiv, azaz a modell onmaga is kepes mukodni.)
+++++++++++++++++++
Most hirtelen ezek jutottak eszembe.
Szia
Janos